
Kafka 스터디 중 Producer 의 message 재전송 동작에 대해 궁금증이 생겨 시작해본 실험.
실험 결과 및 코드는 https://github.com/Hyeon9mak/lab/tree/master/spring-kafka 에서 확인할 수 있다.
🔗 상황 가정 및 결론
- kafka producer 가 발송한 message 를 broker 가 수신했으나, 네트워크 이슈로 ACK 응답이 유실 되었다.
- producer 는 일정 시간 내에 ACK 응답을 받지 못했으므로, 동일한 message 를 재발송한다.
- 이 때, producer 는 동일한 partition(broker) 으로 message 를 재발송 할까?
- 혹은 다른 partition(broker) 로 message 를 재발송 할 가능성이 있는가?
사실 producer 내부 동작을 명확히 이해하고 있다면 큰 고민 없이 답을 알 수 있다.
- producer 내부 partitioner 가 message key 를 hash 하여 어떤 partition 으로 보낼지 결정을 진행한다.
- message key 가 동일하다면, 재발송 시에도 동일한 partition 으로 message 를 재발송 한다.
위 과정을 조금 더 자세히 살펴보자.
🔗 Kafka cluster 구조 연상하기
Kafka 는 더 이상 ZooKeeper 에 의존하지 않는 Kraft 모드를 이용하고 있다.
Kraft 모드에서는 controller 들이 메타데이터 관리를 담당하며, broker 들은 controller 들과 주기적으로 통신하여 메타데이터를 갱신한다.
즉, 기존에는 ZooKeeper 가 메타데이터 관리, controller 가 행동대장 역할을 수행했다면
Kraft 모드에서는 controller 들이 메타데이터 관리와 행동대장 역할을 모두 수행하는 셈.
(active controller 1:N standby controller 구조. 당연히 결정은 active controller 가 내린다.)
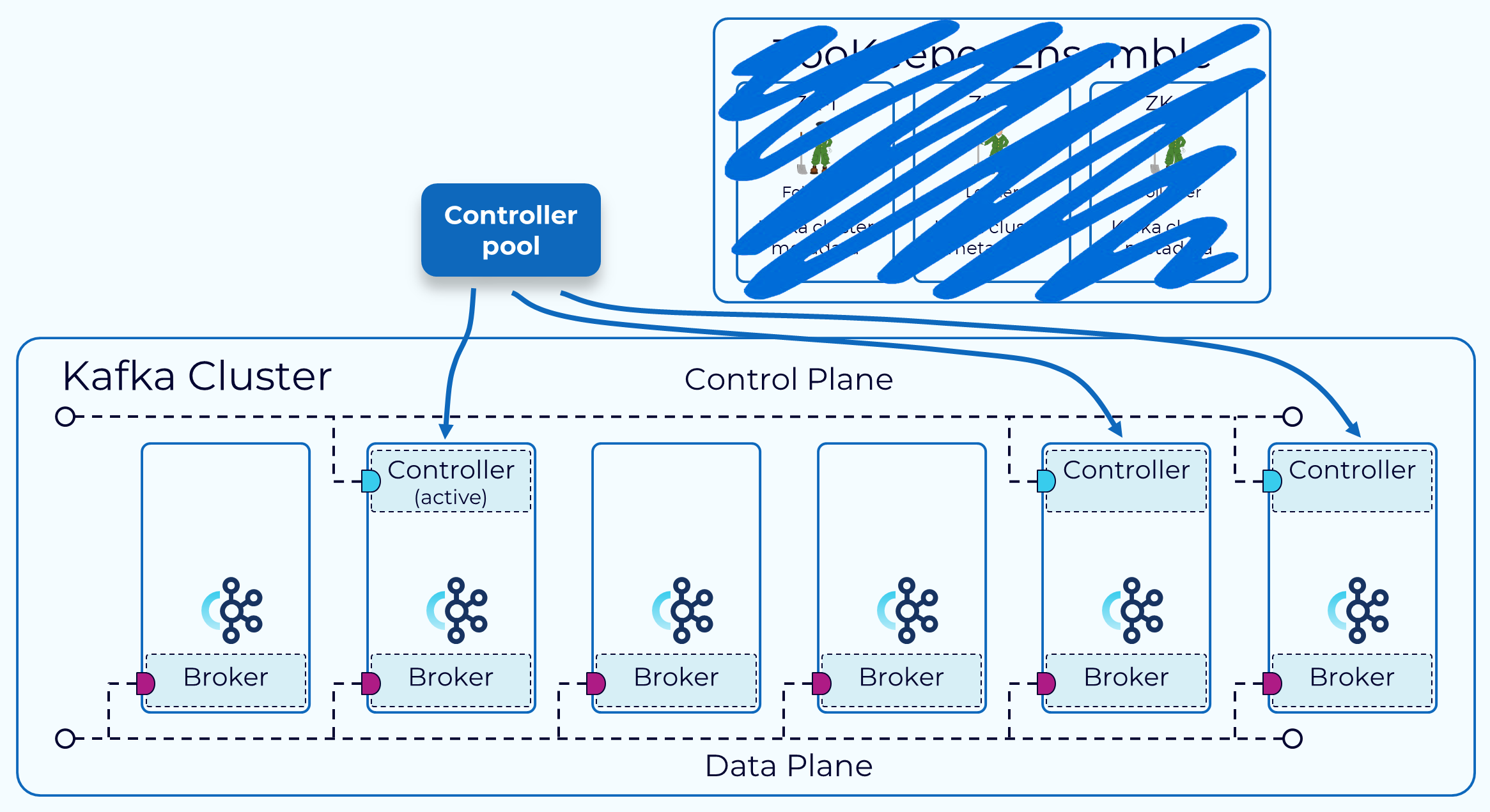
더 자세한 내용은 https://developer.confluent.io/courses/architecture/control-plane/를 참고하면 좋다.
local 에서 kafka cluster 를 구성할 때도 Kraft 모드를 이용할 수 있다.
partition 3개, replication factor 3개로 topic 을 구성한 예시 구조를 살펴보자.
각 broker 들은 partition-0, partition-1, partition-2 를 각각 leader 로 나눠 갖고 관리하고 있다.
나머지 follower partition 들은 broker 장애에 대비하여 다른 broker 에 분산 배치되어 가용성을 확보중이다.
(Leader 의 Sync 를 잘 따라오는 follower partition 들을 ISR(In-Sync Replica) 로 부르며, 언제든지 Leader 승격이 가능하도록 관리된다.)
🔗 Producer partitioner 이해하기
Kafka producer 는 message 를 보낼 때, 내부적으로 떤 partition 으로 보낼지 결정하는 partitioner 의 도움을 받는다.
kafka 4.1 버전 기준 기본 partitioner 는 message key 를 hash 하여 partition 을 결정한다.
이를 기준으로 생각해보면, ACK 응답이 유실되어 재발송이 발생하는 상황에서도 동일한 message key 로 hash 를 수행하므로, 동일한 partition 으로 message 를 재발송 한다는 것을 예측할 수 있다.
🔗 실제 발송 테스트
실제 동일한 message key 로 여러차례 발송을 진행하며 로그를 확인해보면 아래와 같이 동일한 partition 으로 message 가 발송되는 것을 확인할 수 있다.
message key 를 계속 바꾸면서 발송을 진행하는 경우, 아래와 같이 다양한 partition 으로 message 가 발송된다.
🔗 번외 - broker 장애 시 재발송 동작 추론
만약 일시적인 네트워크 이슈로 ACK 를 유실한게 아니라, broker 자체 장애가 발생했다면 어떻게 동작이 달라질까?
(controller 까지 함께 장애가 발생했다고 가정한다.)
1. broker-1 장애 발생
- producer 는 계속해서 같은 partition-0 으로 message 재발송을 진행한다.
- (Kraft mode 기준) standby controller 사이에서 active controller 장애를 감지한다.
2. controller 승격
- standby controller 사이에서 raft 알고리즘을 통해 새로운 active controller 를 선출한다.
3. partition leader 승격
- 새로운 active controller 가 ISR(In-Sync Replica) partition 들 중 하나를 선택하여 partition-0 leader 로 승격시킨다.
4. producer metadata 갱신
- broker-1 이 응답하지 않음을 이상하게 여긴 producer 는 다른 broker 들에게 metadata 갱신 요청을 보낸다.
- 새로운 active controller 로부터 최신 metadata 를 전달받아 내부 정보를 갱신한다.
5. 재발송 성공
- 이후 같은 partition-0 으로 재발송을 시도하고, 새로운 partition-0 leader 인 broker-2 로부터 ACK 응답을 받게 된다.
만약 controller-1 이 살아있는 상태에서 broker-1 이 장애가 발생했다면, controller-1 이 ISR 중 하나를 Leader 로 승격 후 producer 에게 알림을 보내는 과정부터 시작되었을 것이다.

댓글남기기