
💿 Overview
Spring Batch 는 주로 대용량 데이터를 효율적으로 자동 처리하기 위해 사용한다.
batch 작업 특성상 실시간 성이 떨어지는 경우가 많아 성능이 크게 중요하지 않지만, 데이터 양이 너무 많아 처리 시간이 지나치게 오래 걸린다던지, 다른 작업과 연결되어 최소한의 처리 시간이 요구되는 경우도 분명히 존재한다.
이 때 Spring Batch 가 제공하는 병렬 처리 전략을 활용하면 작업 처리 시간을 크게 단축시킬 수 있다.
이번 글에서 Spring Batch 병렬 처리 전략을 알아보기 위한 목차는 아래와 같다.
- Spring Batch 병렬 처리 전략 필요성
- Spring Batch Step 에서 데이터를 처리하는 단위
- Spring Batch 병렬 처리 전략들의 특징
- AsyncItemProcessor
- Multi-threaded Step
- Partitioning
- 시나리오별 권장 전략
💿 Spring Batch 병렬 처리 전략 필요성
batch 작업을 병렬로 처리하고 싶을 때 Spring Batch 에서 제공하는 병렬 처리 전략 외 직접 구현하는 것도 가능하다. 대표적으로 CompletableFuture, Kotlin Coroutines 등을 활용해 비동기적으로 작업을 처리하는 방법이 있다.
// 기본적인 처리 로직
fun processItem(item: Item): ProcessedItem {
return ProcessedItem(item)
}
기본적인 item 처리 로직을 병렬로 처리하고 싶다면, 아래와 같이 Collection(List) 와 함께 CompletableFuture 를 활용할 수도 있다.
// CompletableFuture 를 이용한 병렬 처리 로직
fun processItems(items: List<Item>): List<ProcessedItem> {
val executor = Executors.newFixedThreadPool(10)
return try {
items.map { item ->
CompletableFuture.supplyAsync({ ProcessedItem(item) }, executor)
}.map { it.join() }
} finally {
executor.shutdown()
}
}
그러나 Spring Batch 에서 제공하는 병렬 처리가 아닌 경우 여러가지 문제가 생기기 쉽다.
Collection 단위로 인해 발생하는 비효율
processItems 메서드 파라미터로 넘어온 1,000,000 건의 데이터들 중, 1건의 데이터에 문제가 발생하여 Retry 가 발생했다고 가정해보자.
단 1건의 데이터에 문제가 발생했음에도 불구하고, processItems 메서드 내부에서는 1,000,000 건의 데이터를 모두 처리해야 한다.
Skip 은 어떨까? 1,000,000 건의 데이터들 중, 1건의 데이터에 문제가 발생하여 Retry 가 발생했다고 가정해보자. 1건을 제외하고 정상 처리가 가능한 999,999 건의 데이터가 모두 Skip 된다.
Transaction 관리 부담
Spring 은 기본적으로 ThreadLocal 을 이용해 Thread 단위의 Transaction 을 관리한다. 따라서 Spring Batch Step 내부에서 별도의 병렬 처리 코드를 작성하는 경우, 병렬 처리에 사용된 Thread 들은 Step 의 Transaction Context 를 공유하지 못한다.
새롭게 생성된 Thread 들은 Step 의 Transaction Context 를 알지 못하기 때문에 Transaction 을 보장 받지 못한다.
- Step Chunk Thread 가 rollback 될 때, 병렬 처리에 사용된 Thread 들의 작업은 rollback 되지 않는다.
- JPA 사용 환경에서 lazy loading, persistence context 등을 활용할 수 없다.
예외 처리 복잡도 증가
Spring Batch 에서는 Step 을 생성하는 과정에서 Chunk 단위 데이터 처리에 Skip, Retry 와 같은 강력한 예외 처리 기능을 설정할 수 있다. Spring Batch 에서 제공하는 병렬 처리 전략을 이용하는 경우 이를 자연스럽게 활용할 수 있으나, 직접 병렬 처리를 구현하는 경우 Skip, Retry 와 같은 예외 처리 기능을 활용하기 위해 별도 코드 작성이 필요하다. 특히 CompletableFuture 를 사용한 위 예시 같은 경우, 예외가 CompletionException 으로 감싸져 전파되기 때문에 아래와 같은 추가 예외 처리가 필요하다.
fun processItems(items: List<Item>): List<ProcessedItem> {
val executor = Executors.newFixedThreadPool(10)
return try {
items.map { item ->
try {
CompletableFuture.supplyAsync({ ProcessedItem(item) }, executor)
} catch (exception: Exception) {
throw exception.cause ?: throw exception
}
}.map { it.join() }
} finally {
executor.shutdown()
}
}
Spring Batch 병렬 처리 전략은 만능인가?
Spring Batch 가 제공하는 병렬 처리 전략들은 앞서 언급한 문제점들을 효과적으로 해결할 수 있다. 그러나 Spring Batch 병렬 처리 전략들 또한 완벽하지는 않다. 명백한 제약사항과 단점 또한 존재하기 때문에, 각 전략들의 특징을 명확히 이해해둔 후 각 상황별로 적합한 전략을 채택해서 활용하는 지혜가 필요하겠다.
💿 Spring Batch Step 에서 데이터를 처리하는 단위
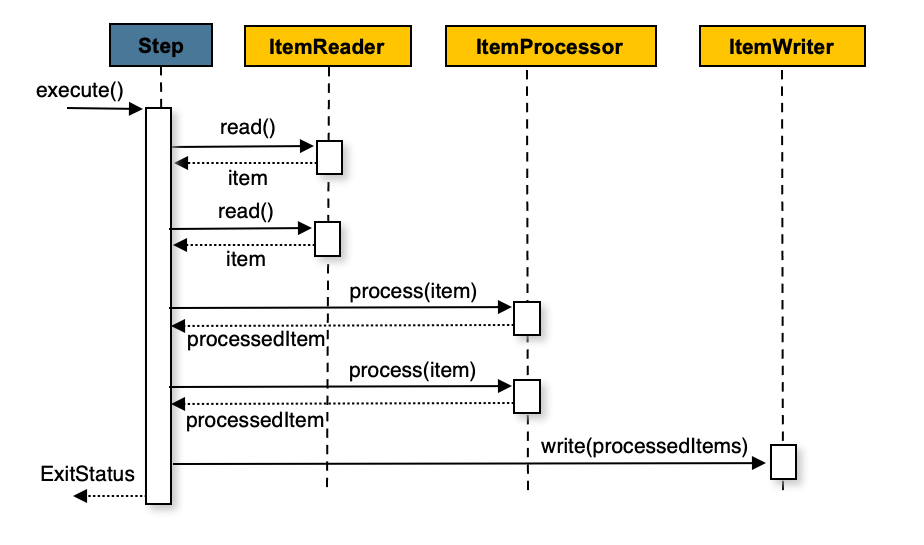
대부분의 대량 데이터를 처리할 땐 Chunk 기반의 처리 방식(Chunk-oriented Processing)을 사용한다.
Chunk 기반 처리 방식은 Step 이 데이터를 일정 단위로 읽고(Read), 처리하고(Process), 기록(Write)하는 방식을 의미한다.
그림을 자세히 살펴보면 read() - read() - process() - process() - write() 와 같은 흐름을 갖고 있다.
즉 Chunk 기반 처리 방식에서 각 작업들은 아래와 같은 특징을 갖는다.
- Reader: Item 단위로 하나씩 데이터를 읽어온다. 이를 Chunk 수 만큼 반복한다.
- Processor: Reader 가 읽어온 Item 단위 데이터를 가공한다. Processor 가 없는 경우 Reader 가 읽어온 Item 을 그대로 Write 로 전달한다.
- Writer: Item 들을 모아 Chunk 단위로 한꺼번에 기록한다.
ItemReader Paging 처리
Reader 에서 실제 Item(데이터) 단위로 RDB 에 query 를 수행하는 것은 지나치게 비효율적이이다.
그렇다고 모든 데이터를 한꺼번에 읽어오는 것 또한 메모리에 부담이다.
때문에 Reader 내부적으로는 Paging 처리를 이용해서 적정한 크기의 데이터를 읽어오도록 한다.
이를 List<Item> 단위로 Processor 에게 넘길 수도 있고, Iterator 를 이용해 Item 단위로 하나씩 넘길 수도 있다.
아래와 같은 예시를 들어보자.
- RDB 에 10,000 건의 데이터가 존재한다.
- Chunk 크기를 1,000 으로 설정한다.
- Reader 는 Paging 처리를 이용해 한 번에 100 건의 데이터를 읽어온다.
이 때 Iterator 를 이용해 하나씩 넘기는 과정을 살펴보면 다음과 같다.
- Reader 가 100 건의 데이터를 읽어온다.
- Reader 가 읽어온 100 건의 데이터를 Item 단위로 하나씩 Step 에 전달한다.
- Step 은 Item 단위로 Processor 를 호출해 데이터를 가공한다.
- Step 은 가공된 Item 들을 모아 Chunk 크기(1,000) 가 될 때까지 대기한다.
- Step 은 Chunk 크기(1,000) 가 될 때마다 Writer 를 호출해 데이터를 기록한다.
- 위 과정을 모든 데이터(10,000 건) 가 처리될 때까지 반복한다.
💿 AsyncItemProcessor
AsyncItemProcessor 는 Chunk 동작 단위 중 process 단계에서 새로운 thread 를 할당해 비동기적으로 Item 을 처리한다. process 단계가 완료되면 writer 로 Feature 를 넘기고, writer 단계에서 Future 를 종합하여 기록한다.
@Bean
fun eatStep(
jobRepository: JobRepository,
transactionManager: PlatformTransactionManager,
eatableCookLogReader: ItemReader<EatableCookingLog>,
asyncItemProcessor: AsyncItemProcessor<EatableCookingLog, AteCookingLog>,
ateCookingLogAsyncWriter: AsyncItemWriter<AteCookingLog>,
): Step {
return StepBuilder(STEP_NAME, jobRepository)
.chunk<EatableCookingLog, Future<AteCookingLog>>(CHUNK_SIZE)
.transactionManager(transactionManager)
.reader(eatableCookLogReader)
.processor(asyncItemProcessor)
.writer(ateCookingLogAsyncWriter)
.build()
}
@Bean
fun eatableCookLogReader(
jdbcTemplate: JdbcTemplate,
): ItemReader<EatableCookingLog> {
return NoOffsetPagingItemReader(
jdbcTemplate = jdbcTemplate,
chunkSize = CHUNK_SIZE,
)
}
@Bean
fun asyncItemProcessor(): AsyncItemProcessor<EatableCookingLog, AteCookingLog> {
val processor = ItemProcessor<EatableCookingLog, AteCookingLog> { it.eat() }
val asyncItemProcessor = AsyncItemProcessor(processor)
asyncItemProcessor.setTaskExecutor(cookingLogUpdateExecutor())
return asyncItemProcessor
}
@Bean
fun ateCookingLogAsyncWriter(
ateCookingLogWriter: ItemWriter<AteCookingLog>,
): AsyncItemWriter<AteCookingLog> {
return AsyncItemWriter(ateCookingLogWriter)
}
@Bean
fun cookingLogUpdateExecutor(): TaskExecutor {
val executor = ThreadPoolTaskExecutor()
executor.corePoolSize = POOL_SIZE
executor.maxPoolSize = POOL_SIZE
executor.setThreadNamePrefix("async-processor-")
executor.setWaitForTasksToCompleteOnShutdown(true)
executor.initialize()
return executor
}
전체 코드는 https://github.com/Hyeon9mak/lab/tree/master/spring-batch-async-item-processor 에서 확인할 수 있다.
기본적으로 병렬 처리에 사용되는 thread 의 수는 SimpleAsyncTaskExecutor 에 의해 결정된다.
SimpleAsyncTaskExecutor 는 가용 가능한 자원만큼 무제한으로 thread 를 생성하기 때문에, 자원 고갈에 따른 OOM 이슈가 발생할 수 있다.
따라서 대량의 데이터가 발생하는 운영 환경에서는 직접 TaskExecutor 를 구현해 적정한 thread 수를 제어하는 것이 좋다.
순서 보장
Chunk 내부의 process 에서 병렬 처리가 수행되므로, Chunk 단위에서는 순서를 보장받을 수 있다.
때문에 ItemStreamReader, ItemStreamWriter 를 사용하는 경우에도 순서가 보장된다.
이름 그대로 process 만 병렬 처리
그림을 통해 이해할 수 있듯, AsyncItemProcessor 는 process 단계에서만 병렬 처리를 수행한다.
때문에 reader, writer 에서 병목이 발생하는 경우 큰 효과를 기대하기 어렵다.
예외 처리
앞서 강조했듯, AsyncItemProcessor 는 process 단계에서 Feature 를 이용한 비동기 처리를 수행한 후 writer 단계에서 Future 를 정리하고 적재한다.
따라서 process 단계에서 예외가 발생한 경우 예외가 Feature 로 wrapping 되어있기 때문에, Feature 를 unwrapping 하는 writer 단계에서 예외가 처리된다.
가령 process 단계에서 BusinessException 에 대한 skip 설정을 해두었어도,
process 단계에서 발생한 BusinessException 은 writer 단계에서 ExecutionException 으로 wrapping 되어 전파된다.
ExecutionException 에 대한 별도 설정을 하지 않았다면 Batch 가 그대로 중단 되는 것이다.
Transaction 관리
AsyncItemProcessor 는 process 단계에서 새로운 thread 를 생성해 비동기적으로 Item 을 처리한다.
따라서 process 단계에서 생성된 thread 들은 Step 의 Transaction Context 를 공유하지 못한다.
이는 앞서 언급한 직접 병렬 처리 구현 시 발생하는 문제점과 동일하다.
💿 Multi-threaded Step
Multi-threaded Step 은 Chunk 단위 동작 전체를 하나의 thread 로 처리한다. 즉 reader, processor, writer 단계가 모두 하나의 thread 에서 처리되는 것이다.
@Bean
fun cookingLogUpdateExecutor(): TaskExecutor {
val executor = ThreadPoolTaskExecutor()
executor.corePoolSize = POOL_SIZE
executor.maxPoolSize = POOL_SIZE
executor.setThreadNamePrefix("multi-threaded-step-")
executor.setWaitForTasksToCompleteOnShutdown(true)
executor.initialize()
return executor
}
@Bean
fun eatStep(
jobRepository: JobRepository,
transactionManager: PlatformTransactionManager,
cookingLogUpdateExecutor: TaskExecutor,
eatableCookLogReader: ItemReader<EatableCookingLog>,
eatCookLogProcessor: ItemProcessor<EatableCookingLog, AteCookingLog>,
ateCookingLogWriter: ItemWriter<AteCookingLog>,
): Step {
return StepBuilder(STEP_NAME, jobRepository)
.chunk<EatableCookingLog, AteCookingLog>(CHUNK_SIZE, transactionManager)
.reader(eatableCookLogReader)
.processor(eatCookLogProcessor)
.writer(ateCookingLogWriter)
.taskExecutor(cookingLogUpdateExecutor)
.build()
}
전체 코드는 https://github.com/Hyeon9mak/lab/tree/master/spring-batch-multi-threaded-step 에서 확인할 수 있다.
Spring Batch 6.0 이전 버전에서는 .chunk<EatableCookingLog, AteCookingLog>(CHUNK_SIZE, transactionManager) 형태로 내부에서 ChunkOrientedTasklet 를 생성하여
각각의 Chunk 단위로 thread 를 할당해서 read-process-write 를 수행할 수 있었다.
그러나 Spring Batch 6.0 부터는 StepBuilder 에서 아래와 같은 형태로 호출 방식이 변경되었다.
@Bean
fun eatStep(
jobRepository: JobRepository,
transactionManager: PlatformTransactionManager,
cookingLogUpdateExecutor: AsyncTaskExecutor, // AsyncTaskExecutor 로 변경
eatableCookLogReader: ItemReader<EatableCookingLog>,
eatCookLogProcessor: ItemProcessor<EatableCookingLog, AteCookingLog>,
ateCookingLogWriter: ItemWriter<AteCookingLog>,
): Step {
return StepBuilder(STEP_NAME, jobRepository)
.chunk<EatableCookingLog, AteCookingLog>(CHUNK_SIZE) // transactionManager 제거 후 별도로 설정
.transactionManager(transactionManager)
.reader(eatableCookLogReader)
.processor(eatCookLogProcessor)
.writer(ateCookingLogWriter)
.taskExecutor(cookingLogUpdateExecutor)
.build()
}
기존 ChunkOrientedTasklet 를 생성하는 대신 ChunkOrientedStep 를 생성하도록 변경되었다.
ChunkOrientedStep 는 read, write 작업은 단일 thread 에서 처리하고, process 작업만 별도의 worker-thread 로 분화하여 처리하는 구조로 변경되었다.
결국 AsyncItemProcessor 와 유사한 구조가 된 것이다.
기존 ChunkOrientedTasklet 을 이용하여 정통적으로 수행되던 Multi-threaded Step 의 구조를 다시 생각해보자.
read-process-write 작업이 모두 하나의 thread 에서 처리되는 특징을 갖고 있다.
그러나 우리는 이미 read/write 를 수행하는 I/O bound 작업이 병렬처리 효율성이 그다지 높지 않다는 것을 예측할 수 있다.
Spring Batch 팀에서도 병렬처리 효율성과 트랜잭션 관리, 재시도 일관성 보장 복잡성 등을 고려하여 ChunkOrientedStep 구조로 변경한 것으로 추측할 수 있다.
Spring Batch 7.0 이후 버전부터는 ChunkOrientedTasklet 가 제거될 예정이므로, Multi-threaded Step 은 사실상 앞으로 사용할 수 없는 전략이다.
💿 Partitioning
Partitioning 은 Step 자체를 여러 개로 나누어 병렬로 처리하는 전략이다.
얼핏 Multi-threaded Step 과 비슷해 보이지만, Multi-threaded Step 는 하나의 Step 내부에서 Chunk 단위로 thread 를 할당하는 반면,
Partitioning 은 Step 자체를 여러 개로 나누어 각각의 Step 을 별도의 thread 에서 처리한다는 차이가 있다.
Partitioning 은 각각의 Step 들이 Context(StepExecution, StepExecutionContext) 를 독립적으로 갖기 때문에, 개별적인 상태 관리가 가능하다.
@Configuration
class CookingLogUpdateJob {
@Bean(JOB_NAME)
fun job(
jobRepository: JobRepository,
eatStepManager: Step,
): Job {
return JobBuilder(JOB_NAME, jobRepository)
.start(eatStepManager)
.preventRestart()
.build()
}
@Bean
fun cookingLogUpdateExecutor(): TaskExecutor {
val executor = ThreadPoolTaskExecutor()
executor.corePoolSize = POOL_SIZE
executor.maxPoolSize = POOL_SIZE
executor.setThreadNamePrefix("partition-thread")
executor.setWaitForTasksToCompleteOnShutdown(true)
executor.initialize()
return executor
}
@Bean
fun eatStepPartitionHandler(
eatStep: Step,
cookingLogUpdateExecutor: TaskExecutor,
): TaskExecutorPartitionHandler {
val partitionHandler = TaskExecutorPartitionHandler()
partitionHandler.step = eatStep
partitionHandler.setTaskExecutor(cookingLogUpdateExecutor)
partitionHandler.gridSize = POOL_SIZE
return partitionHandler
}
@StepScope
@Bean
fun eatStepPartitioner(
@Value("#{jobParameters['startDate']}") startDate: String?,
@Value("#{jobParameters['endDate']}") endDate: String?,
jdbcTemplate: JdbcTemplate,
): CookingLogIdRangePartitioner {
requireNotNull(startDate) { "startDate job parameter is required" }
requireNotNull(endDate) { "endDate job parameter is required" }
val startDateInstant = LocalDate.parse(startDate, DateTimeFormatter.ISO_LOCAL_DATE)
.atStartOfDay(KST_ZONE_ID)
.toInstant()
val endDateInstant = LocalDate.parse(endDate, DateTimeFormatter.ISO_LOCAL_DATE)
.atStartOfDay(KST_ZONE_ID)
.toInstant()
return CookingLogIdRangePartitioner(
jdbcTemplate = jdbcTemplate,
startDate = startDateInstant,
endDate = endDateInstant,
dataCountPerPartition = CHUNK_SIZE,
)
}
@Bean
fun eatStepManager(
jobRepository: JobRepository,
eatStepPartitioner: CookingLogIdRangePartitioner,
partitionHandler: TaskExecutorPartitionHandler,
): Step {
return StepBuilder("eat-step-manager", jobRepository)
.partitioner(STEP_NAME, eatStepPartitioner)
.partitionHandler(partitionHandler)
.build()
}
@Bean
fun eatStep(
jobRepository: JobRepository,
transactionManager: PlatformTransactionManager,
eatableCookLogReader: ItemReader<EatableCookingLog>,
ateCookingLogWriter: ItemWriter<AteCookingLog>,
): Step {
return StepBuilder(STEP_NAME, jobRepository)
.chunk<EatableCookingLog, AteCookingLog>(CHUNK_SIZE)
.transactionManager(transactionManager)
.reader(eatableCookLogReader)
.processor(processor())
.writer(ateCookingLogWriter)
.build()
}
}
전체 코드는 https://github.com/Hyeon9mak/lab/tree/master/spring-batch-partitioning 에서 확인할 수 있다.
Partitioning 에는 크게 2가지 개념의 Component 가 추가된다.
- Partitioner: 조건에 따라 Partition(Step) 을 나누는 역할을 수행한다. 각 Step 들이 처리할 Chunk 범위를 결정한다.
- StepManager: Partitioner 와 나눠진 Partition(Step) 들을 관리한다.
구현이 복잡하다고 느낄 수 있지만, 개념을 이해하고 코드를 따라간다면 크게 어렵지 않다.
Partitioning 도 역시나 별도 설정이 없다면 병렬 처리에 사용되는 thread 의 수는 SimpleAsyncTaskExecutor 에 의해 결정된다.
대량의 데이터가 발생하는 운영 환경에서는 직접 TaskExecutor 를 구현해 적정한 thread 수를 제어하는 것이 좋다.
Transaction 관리
Partitioning 은 Step 자체를 여러 개로 나누어 병렬로 처리하는 전략이다. Chunk 내부 동작은 모두 단일 Thread 에서 처리되기 때문에, Transaction 관리가 아주 쉽다.
순서 보장
Partitioning 은 Step 내부 read - process - write 가 하나의 thread 에서 처리되기 때문에, 각 partition 간 순서를 보장할 수 없다.
다만 Step 내부 에서는 단일 Thread 로, 하나의 StepExecution 과 StepExecutionContext 를 공유하기 때문에 Chunk 단위에서는 순서를 보장받을 수 있다.
때문에 ItemStreamReader, ItemStreamWriter 를 사용하는 경우에도 순서가 보장된다.
Step 간 실패로부터 격리
각 Partition(Step) 들이 독립적인 Context 를 갖기 때문에, 서로 다른 Step 들 간의 실패로부터 격리된다. 가령 Partition(Step) A 가 실패하더라도 Partition(Step) B 는 영향을 받지 않고 정상적으로 완료될 수 있다. 이 모든 결과는 StepManager 가 집계하여 최종 Job 결과로 반영한다.
Partition(Step) A: FAILED
Partition(Step) B: COMPLETED
Partition(Step) C: COMPLETED
------------------
Job: FAILED
이 경우 Batch 를 재시작하여 실패한 Partition(Step) A 만 동작하도록 할 수 있다.
주의할 점은 위와 같은 특성으로 인해 Step 내부에서 Skip 을 잘못 사용할 경우 실패지점을 되찾아 재실행 하기 어려워진다는 것이다.
Partition(Step) A: COMPLETED (1,000 건 중 1건 Skip)
Partition(Step) B: COMPLETED
Partition(Step) C: COMPLETED
------------------
Job: COMPLETED
Partitioning 과 같은 병렬 처리를 고민하는 시점이라면 이미 대량의 데이터를 다루고 있을 가능성이 높다. 때문에 전체 데이터를 다시 처리하는 비효율을 피하기 위해 성공/실패 시나리오를 명확히 구분하고, 설계를 진행하는 것이 중요하겠다.
💿 시나리오별 권장 전략
당연하게 Multi-threaded Step 는 모든 시나리오에서 배제된다.
외부 API 호출이 병목 지점인 경우
- AsyncItemProcessor 권장
- read/write 단계에서 DB I/O bound 가 적은 대신, process 단계에서 API I/O bound 가 큰 경우 유리하다.
- Partitioning 은 구현 복잡도 + Chunk 처리 순서 보장이 어렵다.
CPU 연산이 병목 지점인 경우
- AsyncItemProcessor 권장
- read/write 단계에서 DB I/O bound 가 적은 대신, process 단계에서 CPU bound 가 큰 경우 유리하다.
- Partitioning 은 구현 복잡도 + Chunk 처리 순서 보장이 어렵다.
대량 데이터 통계 집계
- Partitioning 권장
- read/write 단계에서 DB I/O bound 가 큰 경우 유리하다.
- ID, 날짜 등으로 범위를 나눠서 Partition 을 나누어 독립 수행 시키기 좋다.
- 실패시 재실행 지점이 명확하다.
실패 격리가 필요한 경우
- Partitioning 권장
- Partition(Step) 간 실패 격리가 필요한 경우 유리하다.
- 실패한 Partition(Step) 만 재실행 시키기 좋다.
각각의 전략들은 모두 병렬처리를 이용한 성능 향상을 목적으로 하기 때문에, 병렬로 쏟아지는 요청을 받아낼 데이터베이스의 성능도 함께 고려해야 한다. 데이터베이스가 감당할 수 있도록 Connection Pool 크기 등도 함께 꼭 신경써주어야겠다.
References
- Spring Batch Documentation - Chunk-oriented Processing
- https://github.com/spring-projects/spring-batch/wiki/Spring-Batch-6.0-Migration-Guide#new-chunk-oriented-model-implementation
- https://github.com/Hyeon9mak/lab/tree/master/spring-batch-partitioning
- https://github.com/Hyeon9mak/lab/tree/master/spring-batch-async-item-processor
- https://github.com/Hyeon9mak/lab/tree/master/spring-batch-multi-threaded-step

댓글남기기